深入浅出哈希算法:原理、应用与哈希表解析
计算机科学核心基础技术——哈希算法的深度解析。从数学原理到实际应用,覆盖密码安全、数据完整性校验、哈希表数据结构等关键场景,全面掌握哈希技术的核心原理和实战技巧。
哈希(Hash)是计算机科学中一个基础且至关重要的概念,它几乎贯穿了从数据结构到信息安全的每一个角落。然而,其抽象的定义常常使初学者望而却步。本文将借助一个日常生活的场景,为你揭示哈希算法的本质。
核心思想
你可以想象一下,我们拥有一台功能强大的榨汁机。无论向其投入何种水果——一个苹果、一根香蕉,或是一把菠菜——经过机器的处理,最终得到的总是一杯果汁。
这台“榨汁机”的工作过程,恰好映射了哈希算法的三个核心特性:
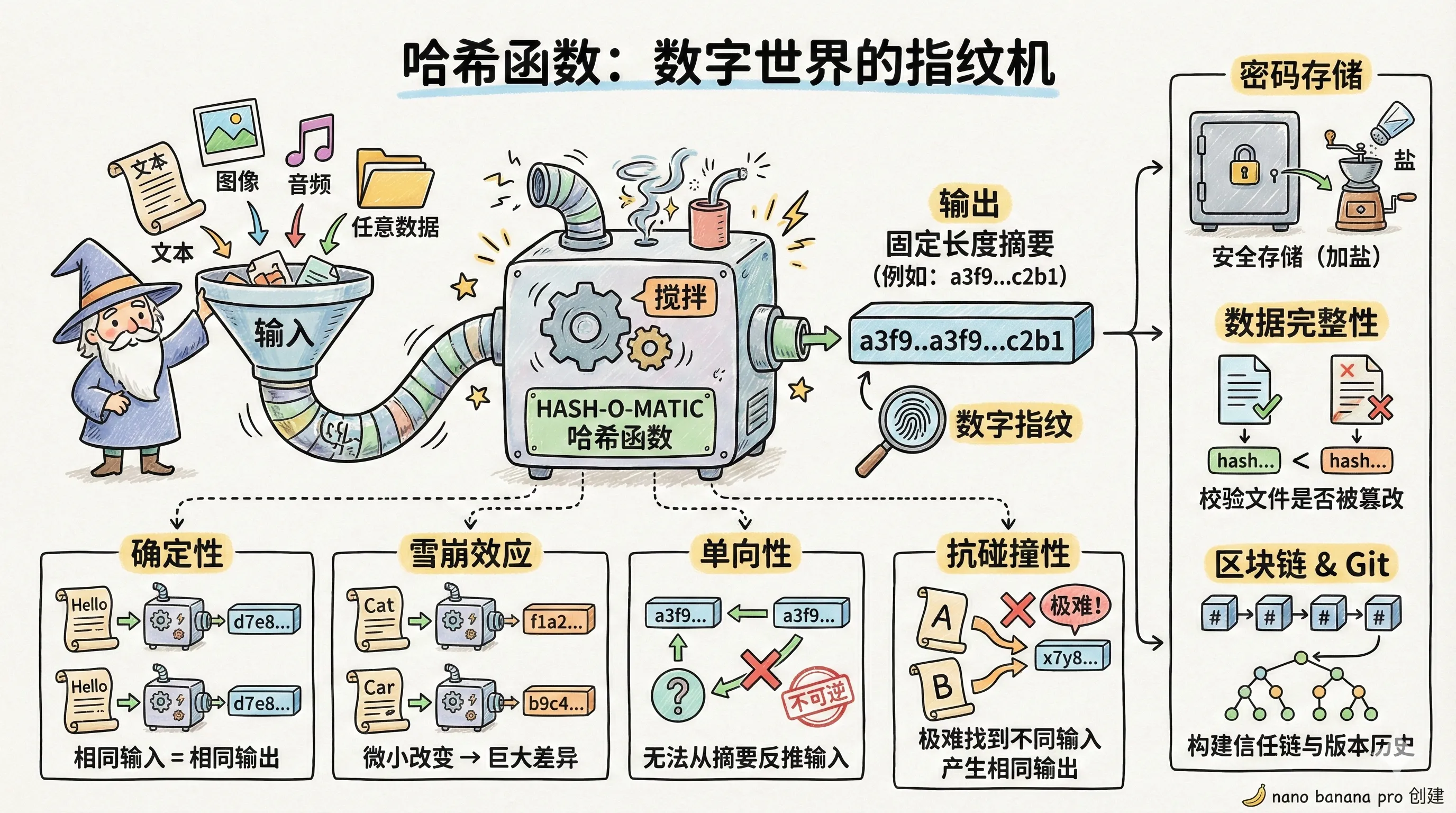
- 定长输出 (Fixed-Length Output):无论输入的水果体积多大、种类多复杂,输出的果汁总是在一个固定容量的杯子里。一个樱桃和一颗西瓜,产出的都是“一杯”果汁。
- 不可逆性 (Irreversibility):如果给你一杯混合果汁,你几乎无法将其精确地还原成原始的苹果、香蕉和菠菜。这个过程是单向的。
- 确定性 (Determinism):只要输入是完全相同的(例如,两个特定品种的苹果和半根香蕉),那么产出的果汁在味道、颜色和浓度上必然是完全一致的。
至此,你已经掌握了哈希算法的核心思想。
哈希的核心概念:哈希函数(Hash Function)是一种算法,它能将任意长度的输入(Input)数据,通过计算转换成一个固定长度的输出(Output)。这个输出值被称为“哈希值”或“摘要”(Digest)。
这个过程就如同信息处理的“榨汁机”,将形态各异的原始数据,压缩成一个紧凑且具有代表性的“数字指纹”。
关键应用
理解了基本概念后,我们来探讨哈希算法在计算机科学中的几个典型应用场景。
1. 用户密码的安全存储
在现代网络应用中,用户的原始密码绝不应该以明文形式存储在数据库中。这会带来巨大的安全风险,一旦数据库泄露,所有用户的账户将形同虚设。
安全的做法是存储密码经过哈希运算后生成的哈希值。其验证流程如下:
- 注册:用户设置密码时,系统计算密码的哈希值,并将该哈希值存入数据库。
- 登录:用户输入密码进行登录时,系统对本次输入的密码执行完全相同的哈希运算,得到一个新的哈希值。
- 比对:系统比对新生成的哈希值与数据库中存储的哈希值是否一致。如果一致,则验证通过。
由于哈希算法的不可逆性,即使攻击者获取了数据库,他们也只能看到一串无规律的哈希值,无法直接反推出用户的原始密码,从而保障了账户安全。
以下是使用 Go 语言 bcrypt 库的示例。bcrypt 是专为密码哈希设计的算法,它会自动“加盐”(Salting),即为每个密码添加随机数据再进行哈希,极大地增加了破解难度。
2. 文件完整性校验
当你从网络上下载大型文件(如操作系统镜像、软件安装包)时,如何确保文件在传输过程中没有损坏或被恶意篡改?
软件发布方通常会随文件提供一串字符,如 SHA256 或 MD5 校验和,这串字符就是原始文件的哈希值。下载完成后,你可以使用相同的哈希算法(如 SHA256)在本地计算已下载文件的哈希值。
如果本地计算出的哈希值与官方提供的值完全一致,则证明文件是完整且未经篡改的。这是哈希算法确定性的直接应用。
使用 Go 计算一个字符串的 SHA256 哈希值:
哈希表 (Hash Table)
哈希表(在许多语言中也称为 Map、Dictionary 或 Associative Array)是哈希思想最杰出、最广泛的应用之一。
我们常用的数组(Array) 是一种线性数据结构,它通过索引(index)来存取元素,访问速度很快。但数组的局限性在于,如果你想查找某个特定内容,却不知道它的索引,就只能从头到尾进行线性搜索(Linear Search)。当数据量巨大时,例如在一亿个用户中查找名为“张三”的用户,这种搜索方式的效率极低。
哈希表(Hash Table) 正是为了解决这一问题而设计的。
哈希表的底层结构通常是一个数组,但它引入了哈希函数作为高效的“地址计算器”。其工作机制如下:
当你向哈希表中存入一个键值对(Key-Value Pair),例如 (key: "张三", value: "用户数据..."):
- 计算哈希:哈希表对
key("张三")应用哈希函数,生成一个哈希值(如2857399)。 - 映射索引:通过取模运算(
哈希值 % 数组长度)将哈希值转换成一个数组的合法索引(如7)。 - 存储数据:将
value("用户数据...")存放在数组索引为7的位置。
当需要查找“张三”的数据时,只需重复上述的哈希计算和索引映射过程,即可直接定位到数组的 7 号索引,从而一步到位地获取数据。这个过程完全避免了遍历。
这种设计使得哈希表的插入、删除和查找操作的平均时间复杂度达到了 O(1),即常数时间级别,其性能几乎不受数据规模增大的影响。
在 Go 语言中,内置的 map 就是一个高效的哈希表实现。
一个必须考虑的问题是:如果两个不同的 key(例如“LiKui”和“LiGui”)经过哈希计算和取模运算后,得到了相同的数组索引,应该怎么办?这种情况被称为哈希冲突(Hash Collision)。尽管一个优秀的哈希算法会尽可能降低冲突概率,但理论上无法完全避免。解决哈希冲突是实现高效哈希表的关键技术,常见策略包括“链地址法”(在冲突的索引位置维护一个链表)和“开放寻址法”(当索引被占用时,向后探测空闲位置)等。
参考文献
- Go Authors. (n.d.). Go maps in action. The Go Blog. Retrieved from https://go.dev/blog/maps