React 如何处理高频的实时数据?
深入解析 React 处理高频实时数据的技术方案,从 Maximum update depth exceeded 错误到批处理优化,完整解决 SSE 推送场景下的性能问题。
最近,我遇到了一个很有意思的 React 问题。
我需要开发一个实时的日志查看器,功能上需要实时展示服务运行的日志。因为这个项目是内部的,我这里大概抽象一下:
后端使用 SSE(Server-Sent Events) 技术,源源不断地把日志推送给前端。
当日志一条一条、不紧不慢地过来时,一切正常。
但是,当我预览一个已经完成的任务日志时,网页卡顿了一下。浏览器控制台显示了一个 React 开发者很熟悉的错误:
Uncaught Error: Maximum update depth exceeded...(错误:超过最大更新深度)
这个错误通常意味着,存在什么组件陷入了无限循环。比如,组件的渲染函数里直接调用了 setState,导致“渲染 → 更新状态 → 触发渲染 → ...”的死循环。
比如这样:
但我的代码并没有这样的逻辑,该使用 useEffect 的地方都使用了。我只是在 SSE 的事件回调里更新状态。
那么,问题出在哪里呢?
问题的根源:高频更新
起初我以为是哪里的更新逻辑不对,让 claude 排查很久都没找到具体问题。在给现有函数增加了不少缓存,比如useMemo,useCallback,甚至 React.memo 都使用上了,仍旧没有解决这个报错。
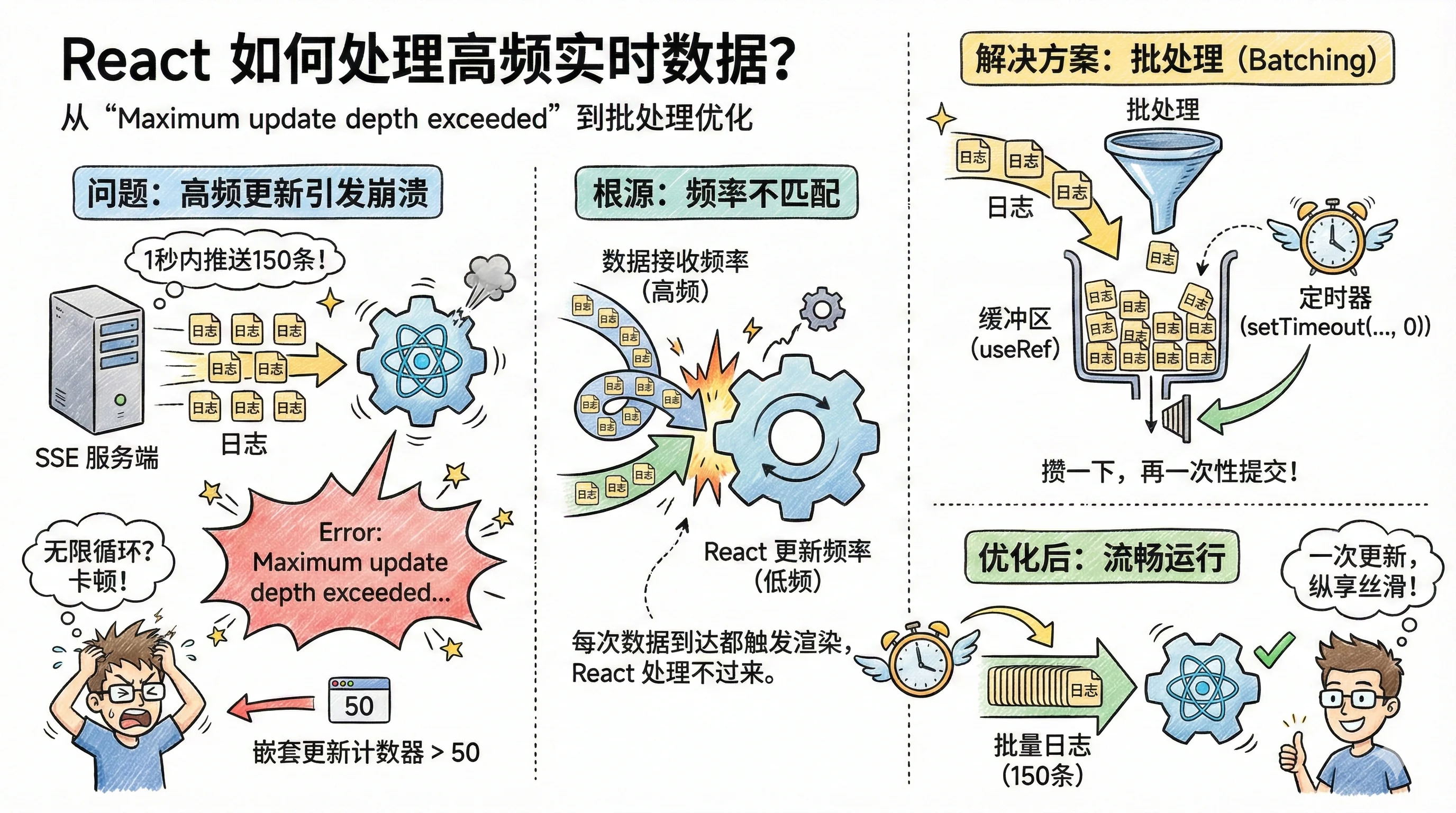
代码没有问题,那么问题就应该出现在一些极端场景导致的高频渲染。比如网络?我才打开控制台的网络部分,看到几乎在很短时间内,上百条的 log 被推送过来!
到这里问题就和清晰了:当服务器在短时间内(比如 1 秒内)推送上百条日志时,每一个 log 都触发了 React 进行重新渲染,这里触发了 React 的某些机制,React 对这种行为发出了报错。
React 内部有一个“嵌套更新计数器”,用来防止无限循环。
简单说,如果在一次渲染(Render)的过程中,又因为某些原因触发了新的状态更新,这就叫“嵌套更新”。当这个次数短时间内超过一个阈值(通常是 50 次),React 就会认为你“可能”写了一个 Bug,于是主动抛出错误,终止程序。
我们的问题就出在这里。SSE 的事件回调来得太快了。
当服务器在 1 秒内推送 150 条日志时,浏览器的事件循环会疯狂执行回调:
- SSE 事件 1 抵达 →
appendLog()→ 触发 React 更新(第 1 次) - React 还没来得及渲染,SSE 事件 2 抵达 →
appendLog()→ 触发 React 更新(第 2 次) - ...
- SSE 事件 50 抵达 →
appendLog()→ 触发 React 更新(第 50 次) - SSE 事件 51 抵达 →
appendLog()→ 触发 React 更新(第 51 次)
在 React 看来,这 51 次更新几乎是“同时”发生的,它无法分辨这是“51 条独立日志”还是“一个死循环”。为了保护自己,它选择了报错。
问题的本质是:数据接收的频率(高频)和 React 状态更新的频率(低频)不匹配。
我们不能每收到一条数据,就立刻更新一次状态。
后续我了解到 React 18 版本对高频渲染的问题进行了优化,但它目前仅适用于 React 事件处理函数内的同步更新。对于 SSE 回调、fetch 回调、setInterval 等异步事件源触发的更新,仍需手动实现批处理。
解决方案:批处理(Batching)
既然不能一条一条地更新,那很自然就想到,能不能把日志“攒一下”,再一次性提交给 React?
这就是“批处理”(Batching)思想。
我们不再是“来一条,更新一次”,而是“来 N 条,更新一次”。
实现这个功能的关键,是需要一个“缓冲区”(Buffer)和一个“定时器”(Timer)。
- 缓冲区:需要一个地方暂存日志,但这个地方本身不能是 React 的
state(否则又触发渲染了)。useRef是最合适的人选。 - 定时器:需要一个机制,在“攒”日志的间隙,把它们统一提交。
setTimeout(..., 0)是这里的法宝。
代码实现
我们来改造一下 log 事件的处理。
首先,在组件里定义缓冲区和定时器:
其次,实现一个“提交缓冲区”的函数 flushBatch:
最后,修改 SSE 的事件处理函数 handleLogEvent:
为什么是 setTimeout(..., 0)?
你可能会问,为什么是 setTimeout(..., 0)?
这是一个很巧妙的技巧。它并不是真的“延迟 0 毫秒”,而是告诉浏览器:“请在当前这一轮事件循环(Event Loop)的同步代码都执行完之后,再执行这个 flushBatch 函数。”
当 150 条日志在短时间内涌入时,会发生什么?
- 事件 1 抵达 →
push到缓冲区 →setTimeout注册一个flushBatch回调。 - 事件 2 抵达 →
push到缓冲区 → 检查定时器,发现已有,跳过。 - 事件 3 抵达 →
push到缓冲区 → 跳过。 - ...
- 事件 150 抵达 →
push到缓冲区 → 跳过。 - (当前宏任务结束,所有同步代码执行完毕)
- 浏览器从任务队列中取出
flushBatch回调,执行。 flushBatch函数将 150 条日志一次性提交给 React。
于是,150 次 setState 调用,被神奇地合并成了 1 次。应用流畅如初。
(完)