从零构建一个 Mini Claude Code:面向初学者的 Agent 开发实战指南
这篇文章源自前两天我做的一次 Agent 开发实战公开课。面向零基础讲清楚"Agent 是什么"比写代码本身难得多——你不能一上来就甩论文,也不能全程只讲故事。
本次课程相关链接:
源代码仓库:mini-claude-code
Issues 风格教案(本文总结自此):mini-claude-code/issues
Mini Claude Code: mini-claude-code
Vercel AI SDK 快速上手:Vercel AI SDK 最小用法
Memo Code:Github/minorcell/memo-code
这篇文章源自前两天我做的一次 Agent 开发实战公开课。面向零基础讲清楚"Agent 是什么"比写代码本身难得多——你不能一上来就甩论文,也不能全程只讲故事。
最终的效果还不错,至少最后同学们人手一个能跑起来的Mini Claude Code。本文把整个教学内容重新整理成这篇博客,方便没去现场的朋友回顾,也给想自己动手的朋友们一个完整的指引。
课程目标
在开始之前,先明确一下我们希望达成的学习目标:
- 理解为什么 Agent 可以做事情,而 ChatBot 不能
- 听得懂 ReAct 与 Agent 的基本架构
- 能跑通最小 TypeScript Agent
- 带走工程落地的实际经验
这四个目标也是我们整篇文章的脉络。接下来逐一展开。
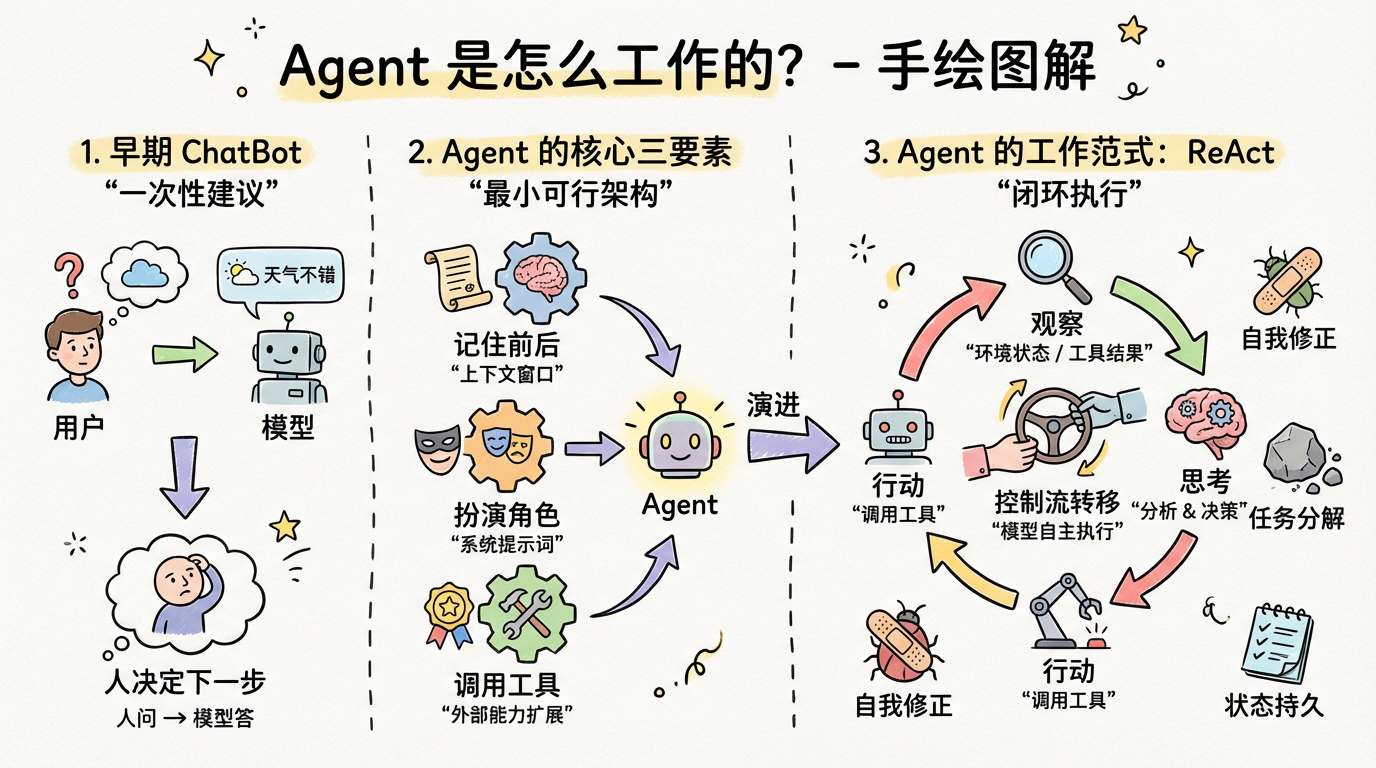
为什么 Agent 和 ChatBot 不一样?
这是个关键问题。澄清了这个,后面很多东西就自然通了。
Agents 的例子
先来看一些 Agent 的实际例子:
- 春节期间的千问:"帮我点一杯奶茶"
- Manus:"帮我做一个个人博客网站"
- Claude Code CLI / Cursor IDE:"帮我修复这个 Bug..."
- OpenClaw:"帮我整理一下谷歌邮件"
- ......
可以看到明显的几个共同点:
- Agent 能做事情
- Agent 能持续执行任务,直到完成目标
- Agent 能和外部系统交互
从 ChatBot 到 Agent 的演进
早期大模型产品,最经典的是 ChatGPT 的网页版本。用户输入提示词,ChatGPT 回复一段文字,这就是"ChatBot"。那时候它可以短暂记住前后说了什么。
比较有意思的是,如果你告诉大模型,让它扮演什么角色、能干什么、不能干什么,它确实会这么做,比如:
- "你是一个小红书博主,你的核心工作是...."
- "你是一个资深的 Web 前端高手,....."
后来,网页版的 ChatGPT 又支持了查询天气、支持网络搜索。比如:"明日上海天气如何?",它便会去查询上海的天气,然后告诉你它查到的结果,并且是用自然语言回复(而不是天气查询接口的原始 JSON 输出):"明天上海天气晴朗,气温约在 16-23 摄氏度,可以穿卫衣出行~"。
三个关键要素
其实到这里就已经不是简单的 ChatBot 了,而是"Agent"。用技术术语来说,这三个要素构成了 LLM-based Agent 的最小 viable architecture(最小可行架构):
怎么实现的?比较成熟的一种方式是 ReAct。
时至今日,Agent 开发范式不止 ReAct 一种。
Plan-and-Execute、Function/Tool Calling + Loop(ReAct Like)等多种模式也有较多的应用。但 ReAct 是最经典、最容易理解的一种,非常适合作为入门。
ReAct——让模型"边想边做"
ReAct(Reasoning + Acting)是 Agent 架构的一种核心范式。它不再是大模型单次输入输出的"问答",而是一个**"观察 → 思考 → 行动 → 再观察"**的循环过程。
一个例子
想象你让 Manus "帮我做一个个人博客网站"。如果是传统 ChatBot,它会给你一段代码和教程,然后结束对话,你需要手动复制粘贴代码到本地测试,有问题之后再把错误发给它,让它再次修复。
但 ReAct 模式下,Agent 会这样执行:
技术实现:控制流的转移
不难看出,ReAct 的关键在于控制流从我们转移到了模型:
具体实现时,一个简单的 Agent 系统提示词可能会包含这样的指令框架:
当模型输出 <action> 时,Agent 框架(如 Claude Code CLI 的运行时)会解析这段 JSON,实际调用对应的工具(落地到代码就是执行一段函数),然后将工具返回的结果以 <observation> 的形式重新注入上下文,再次请求模型,形成闭环。
为什么这能实现"持续执行"?
自我修正能力:如果某一步行动报错(比如代码编译失败),这个错误会作为新的 Observation 回到模型,模型会在 Thought 中分析错误原因,调整 Action(比如修改代码),而不是像 ChatBot 那样等待用户手动修复。
任务分解:面对"帮我修复这个 Bug"这样的复杂指令,模型会在 Thought 中自动拆解:先定位文件 → 阅读相关代码 → 理解逻辑 → 修改 → 测试验证,而不是一次性尝试解决(那样往往失败)。
状态持久:每一轮循环的 Observation 和 Thought 都追加到上下文中,Agent 不会"遗忘"已经完成的步骤(比如已经创建了哪个文件、修改了哪行代码),确保任务连续性。
这正是早期 ChatBot 与现在 Agent 的本质区别:前者是"一次性建议",后者是"闭环执行"。
ReAct Agent 最小架构
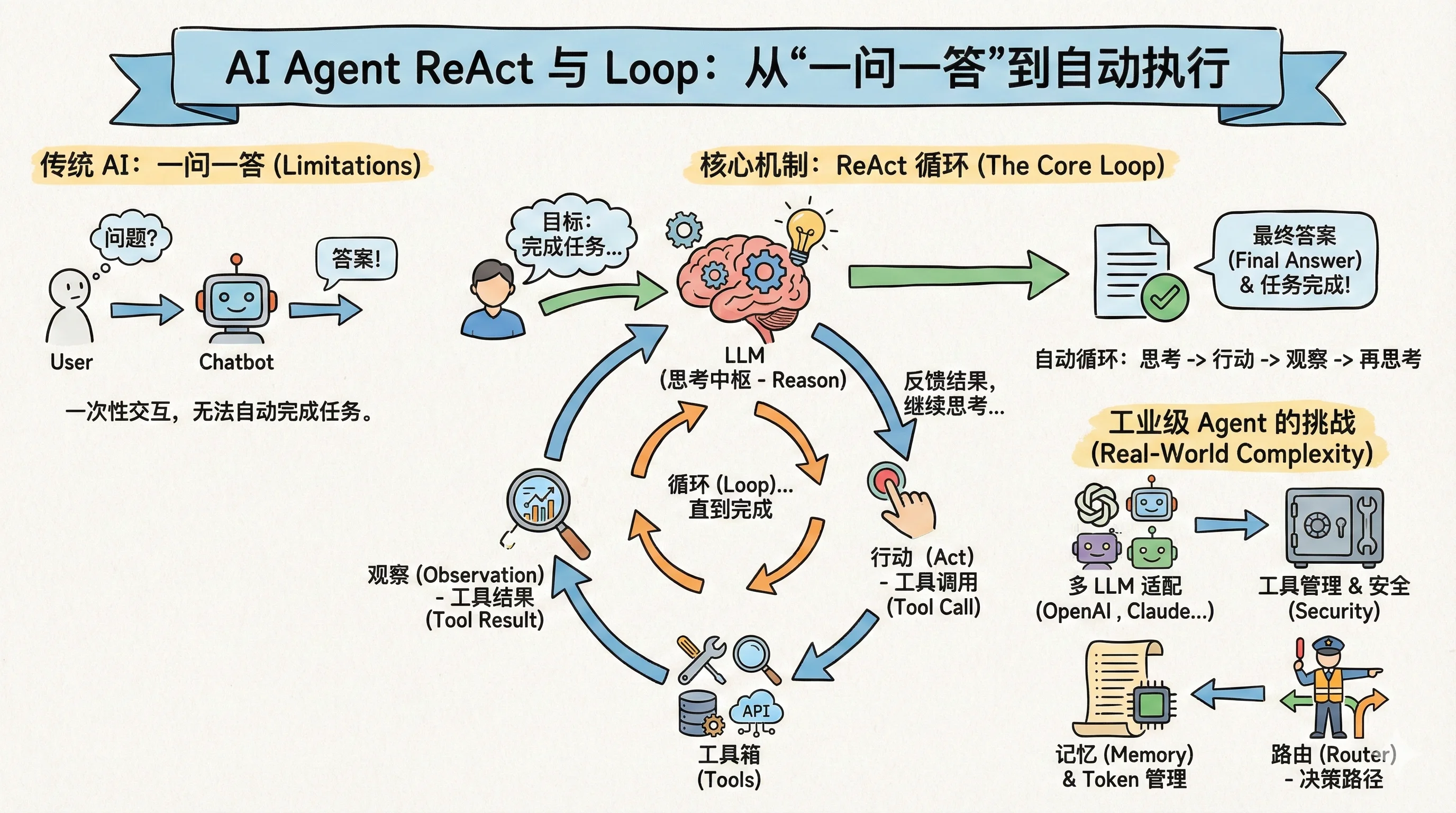
把上面的东西组装起来,Agent 的最小架构可以用一个公式概括:
或者更详细点:
- UI:用户交互界面,CLI、Web、APP 都行
- Tools:让 Agent 支持哪些功能,就需要对应的工具支持
- ReAct:如上文所说,它核心是个 Loop 循环
注解: LLM: 大模型本身,作为整个 Agent 的"脑子" System:系统提示词,通常包含基础提示词、人格设定、工具使用指南等
一个最小可行的 Agent 便是如此。
最小 Agent 实战——天气查询(Bun + TypeScript)
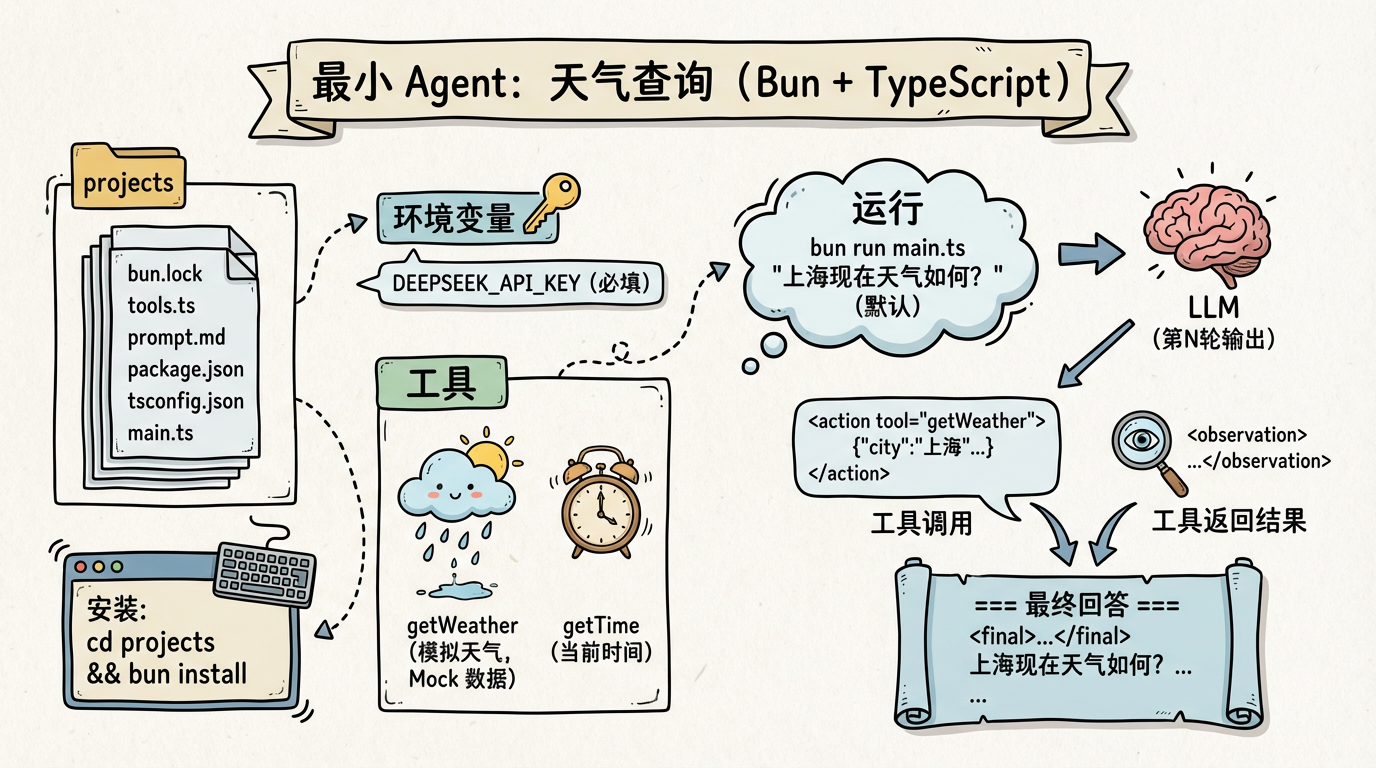
光说不练假把式。我们来动手做一个最小的 Agent。
项目初始化
用 Bun + TypeScript,零依赖:
完整的项目结构如下:
工具定义(tools.ts)
首先定义两个最小集的工具:获取当前时间和查询天气。
系统提示词(prompt.md)
系统提示词告诉模型如何使用这两个工具,以及输出的格式要求。
核心 Loop 代码(main.ts)
这是整个 Agent 的核心——40 行代码实现 ReAct 循环。
运行效果
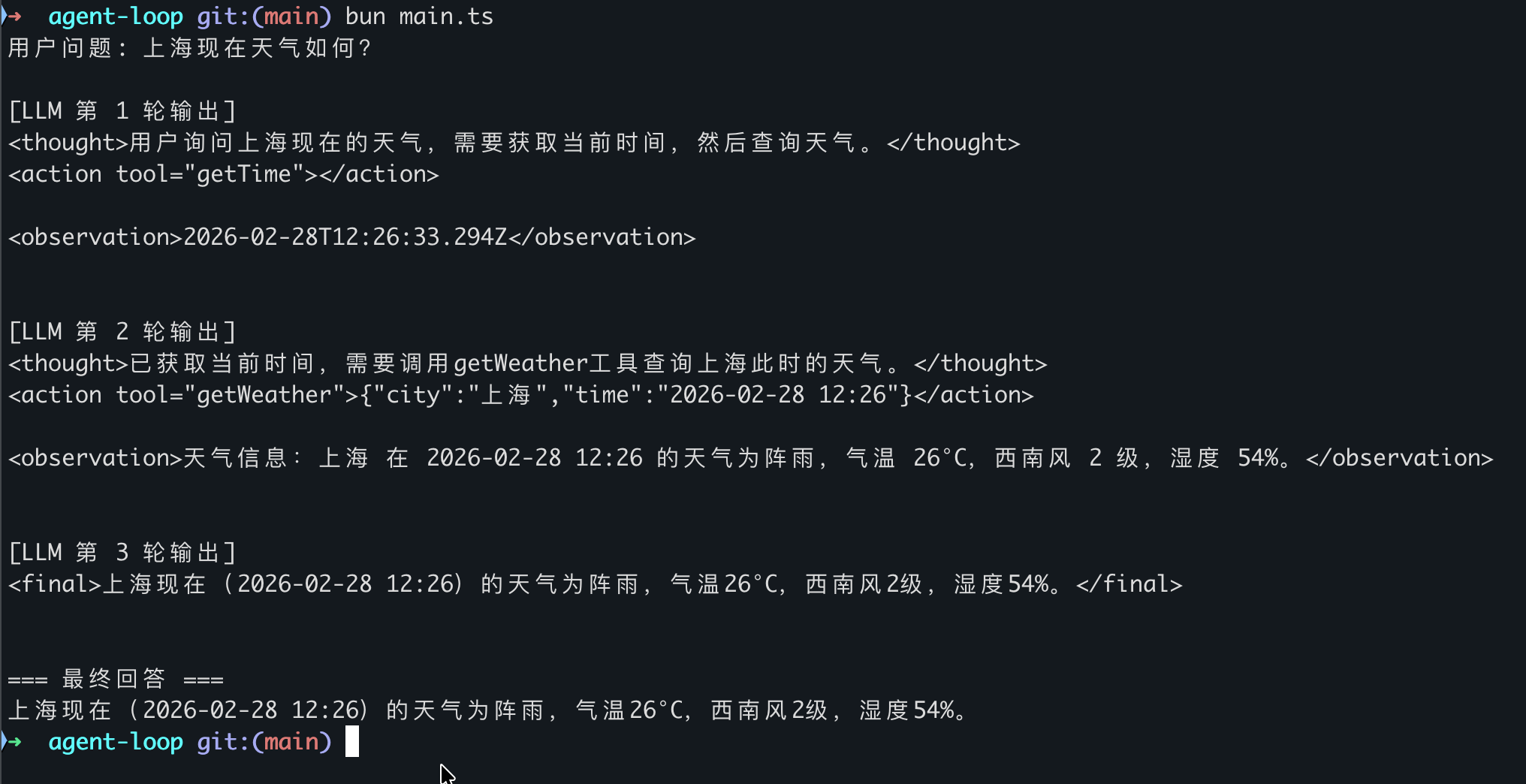
代码解读
这个 40 行的核心循环其实很简单:
- 加载系统提示词——从 prompt.md 文件读取
- 维护一个 history 消息数组——作为 Agent 的上下文记忆
- 循环最多 10 轮:
- 调用大模型,获取输出
- 解析输出:是最终回答就返回,是工具调用就执行工具并把结果填回上下文
- 如果既不是最终回答也不是工具调用,就退出循环
这就是一个最小 Agent 的全部。没有任何复杂的框架,就是一个 for 循环 + 消息数组维护。
Mini Claude Code 设计
有了最小版做基础,我们来做一个更完整的——Mini Claude Code。
先拆 Claude Code CLI
Claude Code CLI 是个超成熟的 Code Agent 范例。要搞 Mini 版,先来简单拆一拆它的核心:
内置工具
- 文件系统:Read File, write_file File, edit_file File, Search Files...
- Bash/Shell:最常用,查 Git、跑复杂命令、执行 Python/Node 代码
- 网络:WebFetch
- 上下文管理:Plan/Todo
- MCP Client
- 子 Agents:进程间交互
上下文
- 压缩机制
- 会话历史:
.claude/sessions/*.jsonl - Skills 系统
为什么会把 Skills 看作是上下文的一种?实际上在 Agent 中,我们的通常做法是在初始化时把 Skills 的索引一同注入到系统提示词里,让模型在需要时调用。它本质上是一个"工具使用指南",一种渐进式纰漏的提示词,但又不是传统意义上的工具,所以我把它归类到上下文管理里。
TUI/CLI
claude mcp ...,claude -c,claude -p,claude -dangerous等用法- 终端交互:slash 命令、IO 流等
Mini 版精简设计
工具设计
Mini 版工具精简到 4 个核心,够用不乱:
- read_file / write_file / edit_file(文件三件套)
- bash(Shell 执行)
- WebFetch(网络请求)
原则:工具别贪多。每多一个,模型负担就加重。Unix 哲学——一工具一事,但组合无限。
技术选型:为什么用 Vercel AI SDK?
之前天气 Demo 用原生 fetch 调用 LLM,手动解析 SSE。零依赖好理解,但生产级有几个问题:
问题 1:多 Provider 适配成本高 换一个模型提供商(OpenAI → Anthropic → Gemini),就要重写请求 URL、Header 格式、响应解析逻辑。
问题 2:工具调用状态机要自己维护
agent-loop 里的 for 循环、parseAssistant()、往 history 里推 observation,这些都是在手写一个工具调用的状态机。稍有差错,模型就会丢失上下文。
问题 3:没有类型安全
工具的输入参数是一个裸字符串,解析 JSON 要靠 try/catch,参数字段靠字符串 key 访问,TypeScript 无法帮你检查。
Vercel AI SDK 解决了这三个问题:
- 用
createOpenAI创建 Provider,换模型只改一行 generateText+maxSteps内置了工具调用状态机,自动处理多轮循环- 用
zod定义参数 schema,工具的execute函数拿到的是已解析、有类型的对象
Vercel AI SDK 的详细用法请见:Vercel AI SDK 最小用法
为什么不用 LangChain / LangGraph?可以思考一下——它们很强大,但对于"理解 Agent 核心原理"这个目标来说,引入的复杂度可能大于带来的价值。
Mini Claude Code 实际代码
来看 Mini Claude Code 的实际项目结构:
详细代码在仓库:mini-claude-code
Provider 配置(provider.ts)
换模型只需要改一行:
工具定义(tools/index.ts)
用 Vercel AI SDK 的 tool() + zod 定义工具:
注意这里的类型安全:参数由 zod schema 定义,SDK 自动解析,execute 函数拿到的 { path, content } 是有类型的对象,不是字符串。
核心 Loop(agent/loop.ts)
很魔法的一点,SDK 自动处理了工具调用循环。我们只需要:
- 配置 model
- 注册 tools
- 设置 maxSteps
SDK 就会自动完成:调用模型 → 检测到工具调用 → 执行工具 → 填回结果 → 再次调用模型 → ... → 直到生成最终回答。
运行效果
这里我们问 Mini Claude Code 这是什么项目,效果如下:
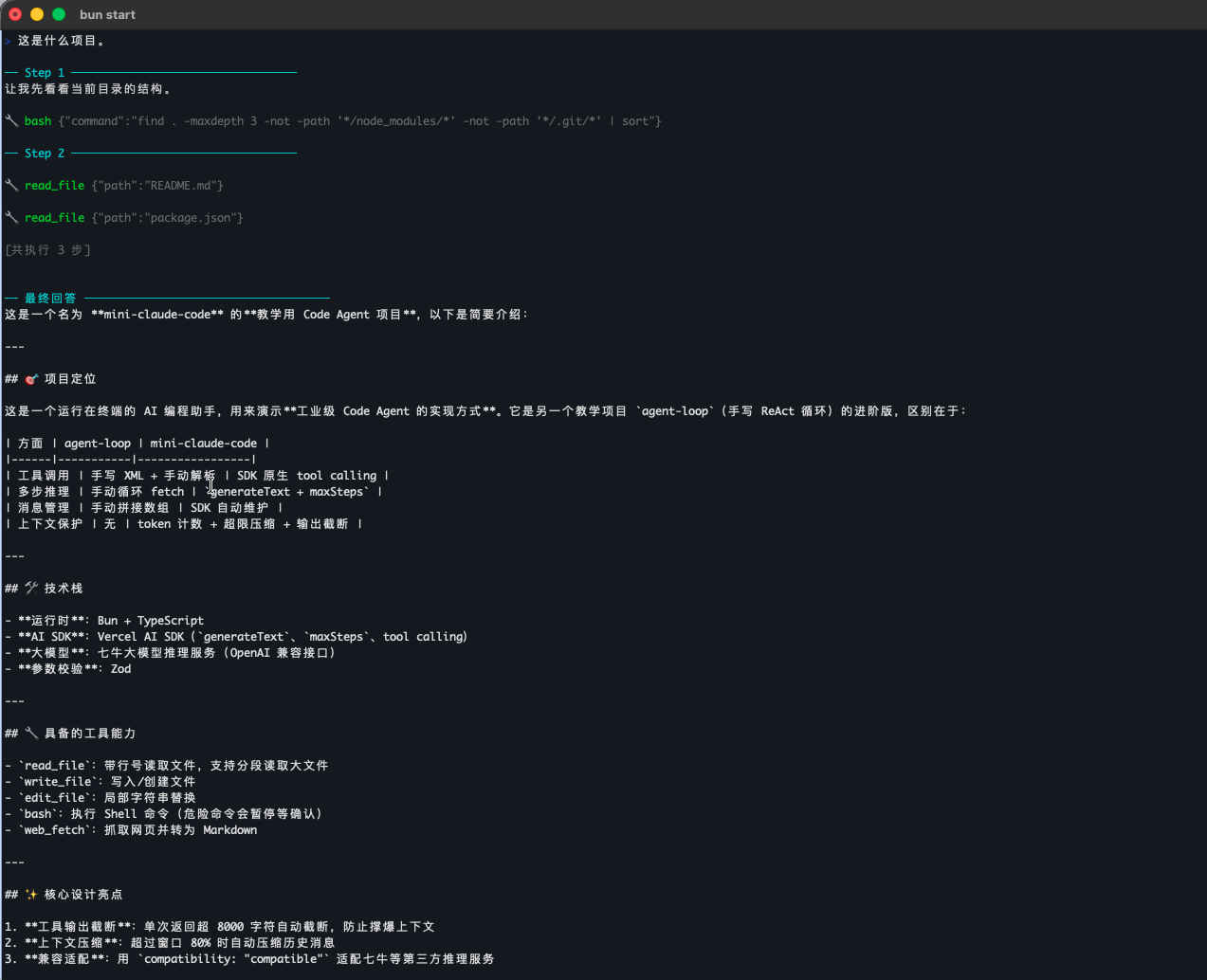
比较有意思的是,还让他给自己写了一个介绍网页:
与手写版本的对比
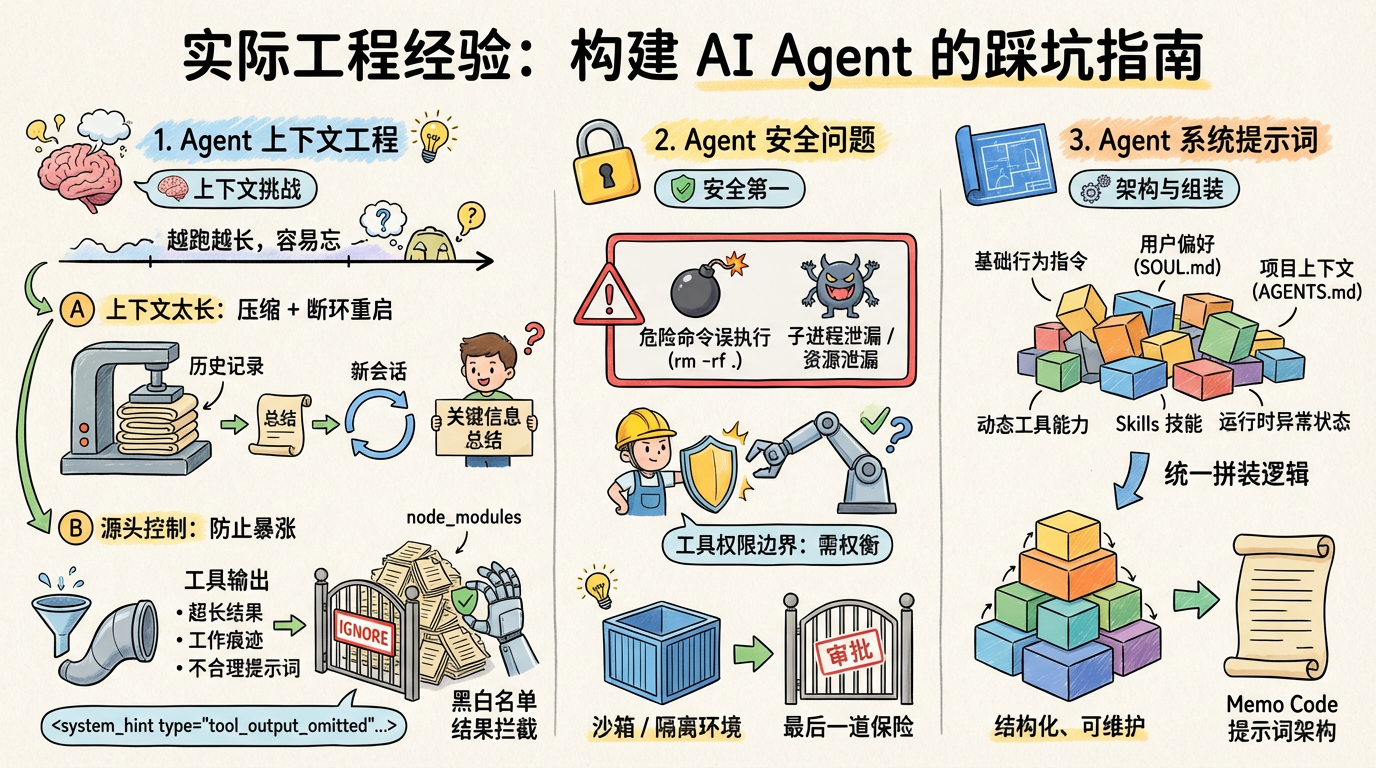
一些实际工程经验
我接触 Agent 开发也算是机缘巧合,从最开始大量的使用 Claude Code 等 Code Agent 编程工具、感兴趣然后自己去研究、最后学习、实践着去做。但是没真正下场之前,我以为 Claude Code 这种东西"差不多就那样"。直到我在做 Memo Code 的过程中才意识到:从"能跑"到"能解决真实问题、能稳定投产",中间的鸿沟还是软件工程。
这里我也选一些比较经典的三类 Agent 的工程问题来聊聊,给大家一些经验:
Agent 上下文工程
聊 Agent / 大模型,绕不开上下文:越跑越长、越长越容易忘。通常要从两个入口拆开看:
- 上下文太长了怎么办(模型有固定上下文长度)
- 怎么从源头控制上下文不要暴涨
1)上下文太长:压缩 + 断环重启
通用解法是"压缩"。实现上可以很朴素:做 token 计数;当 session 中 context 的 token 占比超过阈值(比如 80%)时,中断当前 Loop,把历史上下文整体丢给模型,让它总结:
- 已经做了什么
- 还没做什么
- 当前状态 / 关键约束
- 后续注意事项(坑、边界条件、依赖)
然后新开一个会话(或滑动窗口),后续只发送:系统提示词 + 总结 + 新产生的内容。
这一步的关键不在"总结写得多漂亮",而在于它要能支撑下一轮继续干活:信息结构要稳定、可复用、可增量更新。
2)防止上下文暴涨:从源头管住工具输出
真正让上下文爆炸的,很多时候不是用户对话,而是:
- 工具返回的超长结果(search / read / list)
- MCP 工具的"工作痕迹"(日志、堆栈、长 JSON)
- 不合理的提示词(把无关信息一次性塞满)
举个经典例子:TS 项目里的 node_modules,比宇宙还深还大。模型调用 search 去扫项目中的 js/ts 文件,如果 Search 工具没有合理的防护机制,工具返回可能直接无限长,一次下来就能把上下文撑爆。
所以工具设计本身非常重要,至少要有两道闸门:
- 黑白名单 / ignore 规则:禁止访问某些目录(建议复用 ignore 库,兼容
.gitignore) - 工具结果拦截:当工具输出超过阈值,要么截断,要么直接返回一个明确的 system-hint,让模型知道"有内容,但被省略了",避免它误以为自己看到了全量信息
比如这种形式就很好(明确、可机器解析、可追踪):
Agent 安全问题
Agent 一旦"能动手",安全问题就不是抽象讨论,而是迟早会发生的事故。
一些我觉得必须认真对待的点:
- 危险命令误执行:
rm -rf /是最经典的例子(早期 Gemini CLI 就踩过)。以及最近"小龙虾误删某高管历史邮件"的故事......这类事故的共同点是:不是模型一定会坏,而是系统缺少最后一道保险 - 子进程泄漏 / 资源泄漏:Agent 工作时会频繁启停子进程,处理不当就容易出现不可控的内存泄漏。我自己就遇到过:Codex 内存泄漏 54GB,电脑死机。这类问题通常不是"优化一下就好",而是要把资源回收当作一等公民
- 工具权限边界:
--dangerous确实能释放双手,但也会释放风险。到底是给"全程全权限",还是"关键操作每次审批",需要按场景权衡:频繁审批会拖慢体验,但无审批的代价可能是灾难级
七牛 Agent 专用沙箱 或者 e2b、Docker 容器等做法是直接提供给 Agent 一个隔离环境,与用户本地环境隔离开。
可以参考做法:Memo Code 安全设计:子进程、命令防护与权限审批的统一方案,这里不做过多赘述。
Agent 系统提示词
系统提示词怎么写的"内容套路",市面上已经很多了。这里更想聊工程层面的格式与组装:什么样的提示词结构更利好大模型、也更利好长期维护。
很多人把系统提示词当成一个固定的 Markdown 文件来管,但在真实项目里,系统提示词往往要承载这些东西:
- 基础行为指令(核心身份、输出规范)
- 用户偏好设置(比如
SOUL.md) - 项目级上下文(比如
AGENTS.md) - 动态工具能力(内置工具 + MCP 工具清单/用法)
- Skills 技能(
.agents/skills/skillname/SKILL.md) - 运行时异常状态(截断提示、危险命令拦截、工具降级)
问题是:来源不同、格式不同、优先级不同,而且有些是运行时动态生成的。这就需要一套统一的拼装逻辑(比如分段、打标签、定义优先级、支持增量更新)。
没有最优解,我把自己在做 Memo Code 时的设计思路整理成了一篇文章: Memo Code 系统提示词架构解析:从模板到上下文组装
收尾
这次课程最大的收获其实是回答了一个问题:"Agent 难不难?"
答案是:核心概念不难,40 行代码就能跑起来。但从玩具到真正能解决问题,中间每一步还是软件工程。
希望这篇文章能帮你推开 Agent 开发的大门。代码仓库在这里:mini-claude-code。相关的教案我也直接放在 Issues 里了。
项目里有两个实战案例:
projects/agent-loop—— 纯手写版本,适合理解原理projects/mini-claude-code—— 基于 Vercel AI SDK,适合生产使用
建议先跑通 agent-loop,理解核心循环;再去看 mini-claude-code,学习工程实践。
(完)