从一个想法到可发布:我把博客接进 MCP 的完整实践
这篇不只是复盘一次实现,而是分享一套可复用的接入思路:静态数据产物 + 本地 npx MCP Server + CI 自动发包。
最近看 MUI 文档时,我注意到它已经有 MCP 了。然后我就顺手把本地的 Codex、Claude 这类 code agent 都接进了它的 MCP。
体验非常直接:开发里遇到 MUI 用法问题,Agent 不用我手动贴链接,自己调 mui mcp 就能拿到官方答案。用过一次之后,很容易上瘾。
我这边正好也在做 memo(https://github.com/minorcell/memo-code),最近在补 MCP client / pool / CLI(比如 memo mcp add/remove/list)。越做越觉得,MCP 不只是“大厂工具的生态接口”,它对小工具开发者、库作者、内容站作者也很有价值。
我这次的起点其实很朴素:
我想让别人本地
npx一下,就能把 CellStack 接进 Agent 的 MCP 生态。 最理想的画面是,用户问一句“mcell 最近写了啥”,Agent 直接调工具返回结果,而不是我手动甩链接。
所以这篇想表达的重点,不只是“我实现了一个 MCP server”,而是这套做法本身:
如果你手里有工具、库、内容站,想让 Agent 像调工具一样调用你的内容,这是一条几乎零服务器成本的落地路线。
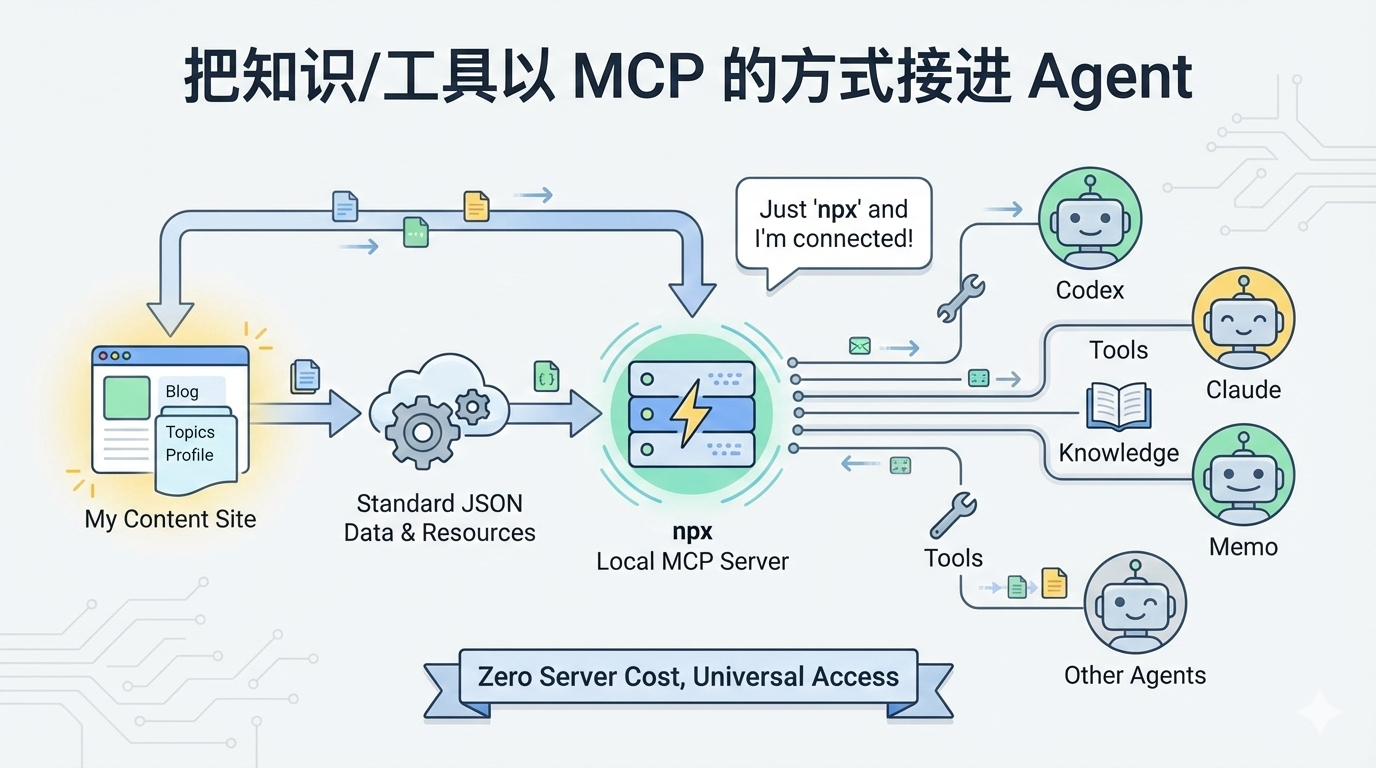
1. 先拆三层:把站点细节从 Agent 侧剥离
我一开始就刻意把方案拆开,避免 Agent 直接依赖站点内部结构:
- 构建期生成静态数据(先把站点内容变成标准 JSON)
- 用户本地起 MCP Server(
@mcell/stack-mcp,npx即用) - Agent 侧 MCP Client 只管调工具,不关心站点怎么组织、页面怎么写
这三层拆完之后,server 的职责就很纯粹:把内容暴露成一组可查询工具,而且是用户本地跑,我不用额外养服务。
第一版很快做出来,但当时模型太“文章中心”,主要只覆盖 blog / topic article。很快我就发现不够:CellStack 不只有文章,还有专题页、站点介绍、关于我这些信息。
如果 Agent 只能读文章,它就更像“文章检索器”,而不是“能回答整个站点内容”的助手。
2. 模型升级成多资源:把“站点”变成可查询资源集合
我把数据模型升级成了多资源结构:
blogtopictopic_articlesite_pageprofile
构建产物也从单一索引,扩成下面这套:
index.jsonlatest.jsoncatalog.jsonarticles/*
同时把站点信息和“我”的信息抽成统一数据源,让页面渲染和 MCP 共用同一份内容,避免维护两套数据。
工具层也同步升级:
list_resourcesread_resourcelist_topicsread_site_info
并且我保留了旧工具名做兼容,避免早期接入方被强制迁移。
3. 真正的坑不在协议,在交付链路
中间踩了两个很真实的坑:
- MCP 握手失败。我一度怀疑是协议问题,最后发现根因是
npx当时还拉不到包(404),stderr 里是 npm 报错。 - 手工发 npm 不稳定。token / 2FA 在“我电脑上能发”不等于“可重复的交付链路”。
这俩问题让我意识到,如果目标是“一句命令接入”,那真正要工程化的不只是 MCP,而是发布与分发。
4. 把发包也工程化:从“能用”到“可持续演进”
后面我把发布流程写进了 CI:
- 构建流程生成 MCP 原数据
- 单独加
publish-stack-mcpworkflow,检测packages/stack-mcp改动后自动发包(版本已存在则跳过)
然后又做了一个很关键的小优化:默认静默启动日志,减少客户端把 stderr 噪音误判成异常;需要排查时再开 STACK_MCP_DEBUG。
到这一步,这件事才算从“能不能做”变成了“可发布、可维护、可演进”。
5. 接入体验:一句命令 + 站点内直接给配置
现在接入基本一句命令:
codex mcp add cellstack -- npx -y @mcell/stack-mcp@0.2.1
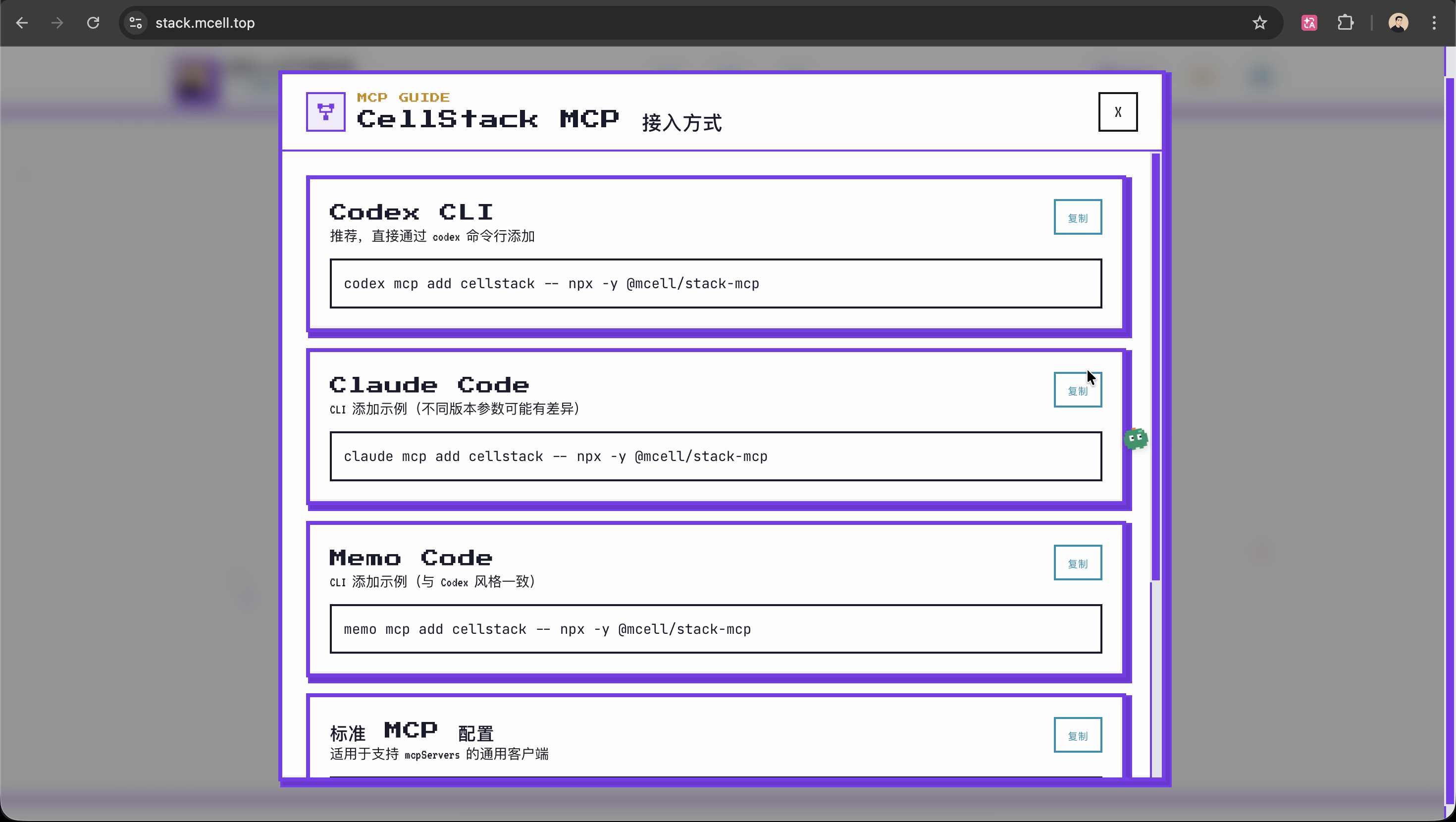
此外我在站点右上角加了 MCP 图标和配置弹窗,直接给 Codex / Claude / Memo / 标准配置的可复制示例,尽量把接入门槛压到最低。
相关记录:
- 设计与实现 issue:https://github.com/minorcell/cellstack/issues/67
- npm 包:https://www.npmjs.com/package/@mcell/stack-mcp
6. 为什么我现在更偏向 MCP(而不只是 skills)
很多人会说“skills 不就行了”。skills 当然有用,但它有个很现实的维护问题:你经常要为不同 Agent 分别写接入说明和配置。
Claude Code CLI、Cursor、Codex CLI、OpenCode……各家入口、目录约定、文档风格都不同。久而久之,一个仓库里会长出一堆 .xxx/ 配置目录,后续改接口、改 schema、加字段时,就得挨个同步、挨个测。
我这次这套 GitHub Pages 静态 JSON + npx 本地 MCP Server 的组合,本质上是把问题收敛成三件事:
- 站点侧:维护一份可演进的标准化数据产物(JSON / catalog / latest / resources)
- 工具侧:维护一个 MCP Server(
npx即用) - Agent 侧:谁支持 MCP 谁就能接,差异只剩“添加 server 的命令怎么写”
这对长期维护“自己的专属知识库”非常友好。后续如果我打算做个人Agent知识库的话,觉得这种做法还是蛮好的。甚至扩展一下,MCP + SKILL的组合也不错,或许长期积累之后,AGENT 即我呢?
(完)